“Streamed audio” means data compression. To reduce the vast amounts of data music streaming services deliver (more than 1 billion streams a day), most of them employ data compression techniques (audio codecs). For example, instead of delivering a large, high-quality .wav file, an AAC or Ogg Vorbis file will be used instead. Unfortunately, these codecs are not very good at handling “hot” audio. What may sound great in the Digital Audio Workstation (DAW) can be easily distorted when converted to a data-reduced audio stream.
Digital audio reduces the analog waveform to a series of discrete measurements (samples). In between these samples, the analog waveform continues smoothly, so in some cases, the reconstructed waveform can be higher than the sample measurements. This is known as an “intersample peak.” The problem, well known in the TV broadcast industry, is that codecs can’t handle intersample peaks, producing distortion as the waveform is incorrectly reconstructed.
Until recently, the only way for the engineer to monitor this behavior was to export the audio from the DAW, apply a compression codec, and listen to the results. While many music streaming services readily publish the necessary information, there are many codecs to consider, and several use different bit rates in different settings (mobile, desktop, premium, etc.), resulting in an extremely arduous and time consuming set of forensic listening tests for the engineer who is willing to take up the challenge.
Fortunately, new tools are becoming available that allow real-time codec auditioning and metering within the DAW. Using a suitable plug-in, it is now possible to monitor several codecs simultaneously and check that inter-sample peaks are not causing downstream codec conversion issues. If codec distortion is a problem, this can then be controlled using an inter-sample (true-peak) limiter to transparently rein in transients that the codec finds difficult to render.
However, the situation is a little more complex than this. As previously mentioned, different bit rates are employed in differing situations. A lower bit rate will involve a higher level of data compression, and low bit rate algorithms tend to be much more susceptible to overload distortion than their higher bit rate counterparts. Optimizing for low bit rates can lead to unacceptable compromises to mix quality in higher bandwidth situations. During listening tests, it soon becomes clear that low bit rate streams suffer many other additional issues over and above overloads due to inter-sample peaks. Bearing this in mind—and the fact that in general, low bit rates are employed in mobile listening environments (meaning ear-buds on the subway, etc.)—it soon becomes apparent that optimizing for high-quality streams is the way forward, where the difference can be appreciated and genuine quality can be preserved.
Codec Listening Tests
Codecs employ several tricks in order to reduce the bandwidth required for music streaming. The first is to remove “perceptually irrelevant” signal components. This technique uses psycho-acoustic models to determine audio, which is difficult (or impossible) to perceive and discards this information in the encoded audio. Strategies include high-frequency limiting, absolute threshold of hearing, temporal masking (sudden loud sounds making it difficult to perceive quiet sounds immediately following) and simultaneous masking (one sound masking another simultaneous sound).
A second level of compression is known as Spectral Band Replication (SBS). When SBS is employed, high-frequency content is discarded, and this information is reconstructed using the remaining low- and mid-frequencies, with guidance from an information stream transmitted alongside.
Finally, in highly data-reduced situations, a technique known as Parametric Stereo (PS) can be employed. Analogous to SBS, in this case, audio is down-mixed to mono and reconstructed to stereo at playout. Yet again, this technique clearly reminds us that mono-compatibility is still a very important aspect of audio production.
Flicking between different bit rate codecs of the same audio is a simple procedure to learn to identify the ‘“sound” of these different processes. A particularly revealing test is to only listen to the ‘“Side” component of a mid/side signal, A/B switching between the original source and encoded signal. Many of the encoding artifacts, which are quite cleverly masked in the full signal, suddenly become extremely obvious as “musical noise” and can then be clearly heard in the full mix once the ear is trained (see Figure 1).
Streaming services have also changed the game in another very important way. Because streaming playlists often have many songs from different artists, genres, and periods in time, the services match the loudness of each song from one to the next, to avoid having the listener constantly reach for the volume control. This is achieved by a process called loudness normalization. Loudness normalization works by analyzing the entire song for its average loudness and then turning it up or down to a set level for the system. As a result, all streaming audio comes out on average, at more-or-less the same loudness.
The implications of this simple change in music consumption are widespread. Previously, it was possible to make a song “stand out” from the competition by using heavy audio compression and limiting. Commonly referred to as “The Loudness War,” this practice led to a situation where making a song as loud as possible became a primary objective.
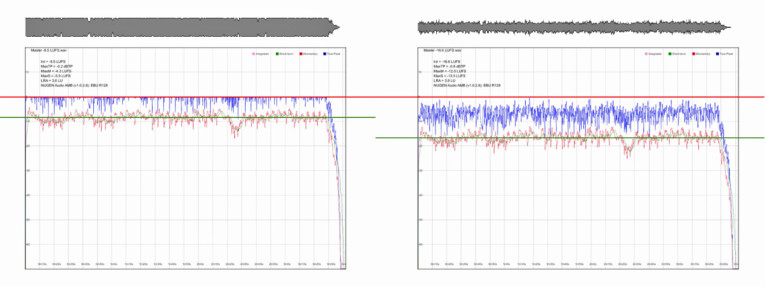
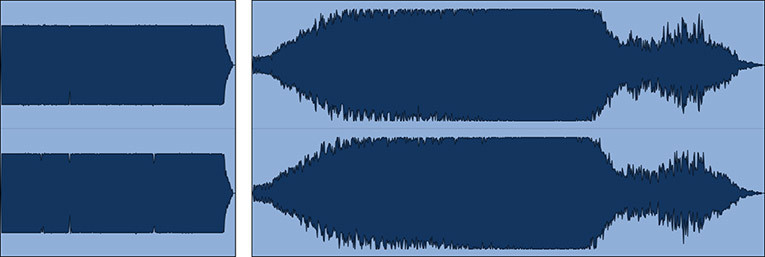
Loudness normalized audio streams remove this “advantage” — it is not possible to make a song louder than the level determined by the playout system (see Figure 2). This means that audio compression and limiting returns to the role of aesthetic enhancement. In fact, in a loudness normalized environment, very heavily limited masters sound flat, lacking presence and detail. Once the master becomes louder than the playout level, the system turns down the level, resulting in audio peaking well below any true-peak limitations, where a less heavily limited version makes use of this available space, capturing more transient detail as a result (see Figure 3).
A less well understood implication is that of macrodynamics. If limiting and codec distortion concerns are primarily to do with retaining microdynamic transient detail, then average song loudness invites us to consider the macrodynamic content — the wider variations between loud and soft within a song.
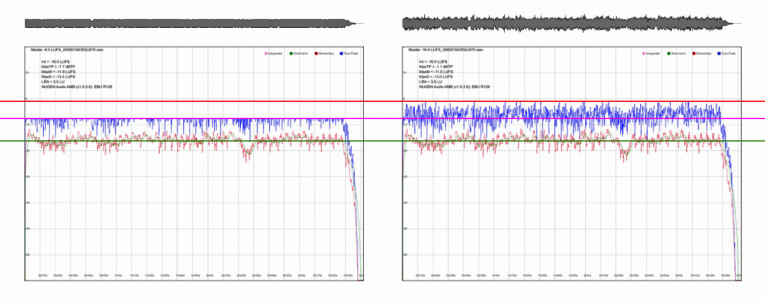
In a peak normalized environment, producers became used to the concept of a maximum level (0 dBFS) relative to which all audio is measured, a ceiling that cannot be exceeded. Loudness normalization changes this concept. The average loudness level is not a ceiling, but rather, the average level across the entire track. It is perfectly possible to have sections well above the average loudness level if they are balanced by sections of relative quiet. A track that takes creative advantage of this situation will have sections that are comparatively very loud when played back-to-back with a heavily limited master that sits on the system playback loudness level, with very little deviation (see Figure 4).
Setting Industry Standards
As audio engineers grapple with these new consumption realities, a new audio descriptor has emerged—Peak to Loudness Ratio (PLR). This concept combines the True-Peak level and average (Integrated) Loudness level into a single parameter. This can be measured for an audio track and can also be used to describe the properties of a playback system. A streaming service can be thought of as having a “letterbox,” defined by a maximum True-Peak level that avoids unacceptable codec distortion, and an average loudness level. With an understanding of system PLR, an audio engineer can now ensure that their audio fits through this “letterbox” without modification.
A related descriptor is Peak to Short-term Loudness Ratio (PSR). This parameter is currently a subject of great interest, as it promises to become a useful, objective, real-time measure of audio dynamics. The Audio Engineering Society (AES) has already published a discussion paper on the subject, with the hope that an industry standard definition can be developed that will help engineers to consistently compare values from different meter manufacturers.
While industry standard metering will certainly help, there is much about today’s playback services that is far from standard. Unlike television broadcasting, there is no universally agreed level of music playback for streaming services. Fortunately, there has been a recent shift toward harmonization, with most of the major players now using fairly similar targets. There is also a great variety of codecs in use, with more coming on stream as the technology develops. A recent trend is that of high-resolution streaming, which promises to remove many of the issues associated with the lossy codecs generally employed today.
There is also work to be done in the area of music aggregation, publishing, and distribution. Even if one were to go to the trouble of producing multiple masters suited to hi-res streams, medium-quality codecs, and different loudness targets, it is difficult (if not impossible) to submit more than one master, which requires pragmatic compromises to be made.
Although there is still much to be resolved, researched, and harmonized, music streaming is here to stay, and has for the first time in years brought a year-on-year increase in revenue for the music industry. While it is a concern that much of today’s music is now heard through a lossy codec, options to listen to a hi-res or non-lossy version are appearing more frequently, and as bandwidth improves, we will see low-quality encoding fade into obscurity. Undoubtedly, the brave new world of Loudness Normalized playback is good news for creative choice, free from the commercial demand to be as loud as possible. There are of course still many minor skirmishes (it takes a long time for old habits to die, especially in Artists and Repertoire circles!), but the Loudness War is over for those who wish to concentrate on making the music sound as good as possible, without having to worry about what everyone else is doing. aX
This article was originally published in audioXpress, June 2018.
About the Author
Jon Schorah is the creative director and co-founder of NUGEN Audio, one of the world’s leading manufacturers of loudness products. Jon has a background in mastering and engineering and has considerable experience in wider aspects of the industry. A 1992 Leeds University (UK) graduate, in recent years Jon has focused on product design with a particular interest in the usability and workflow aspects of audio software.