


CEVA-BX also supersedes special purpose architectures such as audio DSPs and MCUs with DSP extensions; Offers modern processor architecture with high level programming and high efficiency for a broad range of signal processing and control workloads commonly used in consumer, wireless, automotive and industrial applications.
CEVA-BX offers a new breed of DSP architecture, combining the inherent low power requirements of DSP kernels with the high-level programming and compact code size requirements of a large control code base. Using an 11-stage pipeline and 5-way VLIW micro-architecture, it offers parallel processing with dual scalar compute engines, load/store and program control that reaches a speed of 2 GHz at TSMC 7nm process node using common standard cells and memory compilers. The CEVA-BX Instruction Set Architecture (ISA) incorporates support for Single Instruction Multiple Data (SIMD) widely used in neural network inference, noise reduction and echo cancellation, as well as half, single and double precision floating point units for high accuracy sensor fusion and positioning algorithms.
As Mike Demler, Senior Analyst at The Linley Group explains, "Consumer, automotive, industrial and healthcare devices are increasingly integrating multiple sensors, such as cameras, microphones, environmental and motion detectors, which produce data that must be fused, interpreted, and processed on-device before being sent via a wireless link to the cloud. Processing these heavy-duty signal-processing workloads in edge devices requires an efficient combination of control and DSP capabilities.”
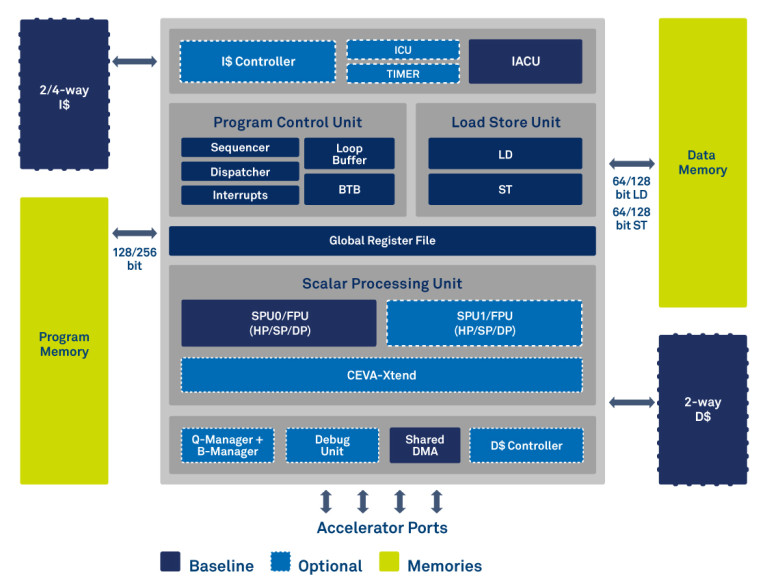
CEVA-BX employs key architecture principles of advanced micro-processor architectures such as a large orthogonal general purpose register set for maximum C compiler efficiency, innovative Branch Target Buffer (BTB) for minimizing branch overhead, hardware loop buffer for reduced power consumption of code loops, fully cached memory subsystem, and native support for all standard C types. Its CoreMark/MHz score of 4.5 reflects the superior control capabilities of the architecture. CEVA-BX users are able to add proprietary ISA into the architecture using the CEVA-Xtend, to accelerate proprietary algorithms and take advantage of CEVA's automatic Queue and Buffer management mechanisms to integrate co-processors and create a cluster of CEVA-BX cores.
“The CEVA-BX architecture revolutionizes the 'all-purpose DSP' concept by offering a high performance hybrid architecture that is a single compute island for all DSP and control workloads that are commonplace in intelligent connected devices. Using a high level programming model and parallel processing it addresses the main performance shortfalls and programming difficulties of older special purpose DSPs and controllers,” says Moshe Sheier, vice president of marketing at CEVA.
The CEVA-BX is initially offered in two configurations - the CEVA-BX1 with single 32X32-bit MAC and quad 16X16-bit MACs and the CEVA-BX2 with quad 32X32-bit MACs and octal 16X16-bit MACs, that are also capable of supporting 16x8-bit and 8x8-bit MAC operations. The CEVA-BX2 addresses intensive workloads such as 5G PHY control, multi-microphone beamforming and neural networks for speech recognition, with up to 16 GMACs per second. The CEVA-BX1 serves low to mid-range DSP workloads, such as cellular IoT, protocol stacks, and always-on sensor fusion, with up to 8 GMACs per second. Security is addressed using dedicated trusted execution modes to comply with the stringent safety standards.

The CEVA-BX family is accompanied by a comprehensive software development tool chain, including an advanced LLVM compiler, Eclipse based debugger, DSP and neural network compute libraries, neural network frameworks support such as Android NN API, ARM NN, and Tensorflow Lite, and choice of industry leading Real Time Operating Systems (RTOS).
The CEVA-BX cores are available now.
www.ceva-dsp.com



